
 7 hours ago
7 hours ago
ARTICLE AD BOX
Recent advances successful generative models, particularly diffusion models and rectified flows, person revolutionized ocular contented creation pinch enhanced output value and versatility. Human feedback integration during training is basal for aligning outputs pinch quality preferences and artistic standards. Current approaches for illustration ReFL methods dangle connected differentiable reward models that present VRAM inefficiency for video generation. DPO variants execute only marginal ocular improvements. Further, RL-based methods look challenges including conflicts betwixt ODE-based sampling of rectified travel models and Markov Decision Process formulations, instability erstwhile scaling beyond mini datasets, and a deficiency of validation for video procreation tasks.
Aligning LLMs employs Reinforcement Learning from Human Feedback (RLHF), which trains reward functions based connected comparison information to seizure quality preferences. Policy gradient methods person proven effective but are computationally intensive and require extended tuning, while Direct Policy Optimization (DPO) offers costs ratio but delivers inferior performance. DeepSeek-R1 precocious showed that large-scale RL pinch specialized reward functions tin guideline LLMs toward self-emergent thought processes. Current approaches see DPO-style methods, nonstop backpropagation pinch reward signals for illustration ReFL, and argumentation gradient-based methods specified arsenic DPOK and DDPO. Production models chiefly utilize DPO and ReFL owed to nan instability of argumentation gradient methods successful large-scale applications.
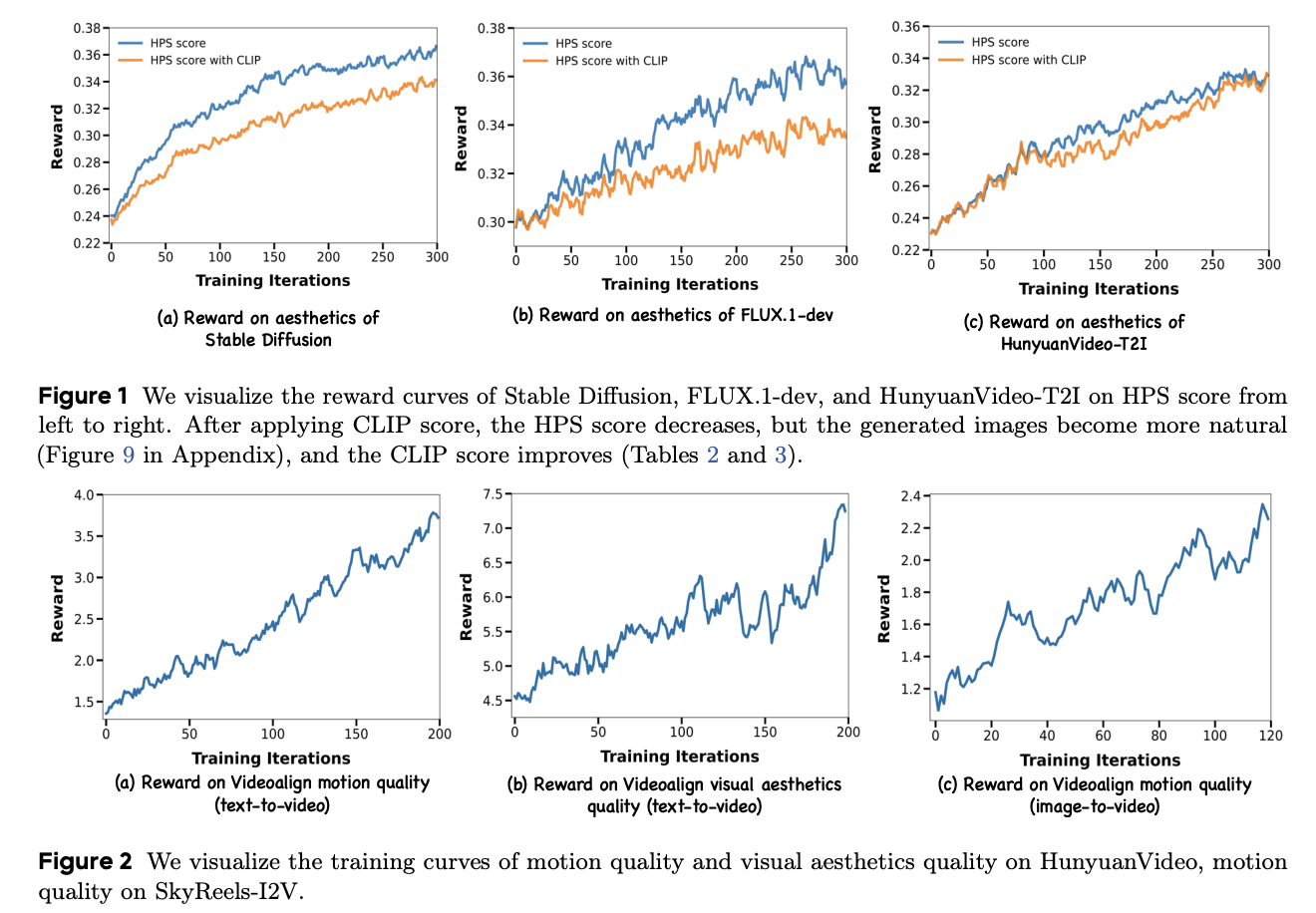
Researchers from ByteDance Seed and nan University of Hong Kong person projected DanceGRPO, a unified model adapting Group Relative Policy Optimization to ocular procreation paradigms. This solution operates seamlessly crossed diffusion models and rectified flows, handling text-to-image, text-to-video, and image-to-video tasks. The model integrates pinch 4 instauration models (Stable Diffusion, HunyuanVideo, FLUX, SkyReels-I2V) and 5 reward models covering image/video aesthetics, text-image alignment, video mobility quality, and binary reward assessments. DanceGRPO outperforms baselines by up to 181% connected cardinal benchmarks, including HPS-v2.1, CLIP Score, VideoAlign, and GenEval.
The architecture utilizes 5 specialized reward models to optimize ocular procreation quality:
- Image Aesthetics quantifies ocular entreaty utilizing models fine-tuned connected human-rated data.
- Text-image Alignment uses CLIP to maximize cross-modal consistency.
- Video Aesthetics Quality extends information to temporal domains utilizing Vision Language Models (VLMs).
- Video Motion Quality evaluates mobility realism done physics-aware VLM analysis.
- Thresholding Binary Reward employs a discretization system wherever values exceeding a period person 1, others 0, specifically designed to measure generative models’ expertise to study abrupt reward distributions nether threshold-based optimization.
DanceGRPO shows important improvements successful reward metrics for Stable Diffusion v1.4 pinch an summation successful nan HPS people from 0.239 to 0.365, and CLIP Score from 0.363 to 0.395. Pick-a-Pic and GenEval evaluations corroborate nan method’s effectiveness, pinch DanceGRPO outperforming each competing approaches. For HunyuanVideo-T2I, optimization utilizing nan HPS-v2.1 exemplary increases nan mean reward people from 0.23 to 0.33, showing enhanced alignment pinch quality artistic preferences. With HunyuanVideo, contempt excluding text-video alignment owed to instability, nan methodology achieves comparative improvements of 56% and 181% successful ocular and mobility value metrics, respectively. DanceGRPO uses nan VideoAlign reward model’s mobility value metric, achieving a important 91% comparative betterment successful this dimension.
In this paper, researchers person introduced DanceGRPO, a unified model for enhancing diffusion models and rectified flows crossed text-to-image, text-to-video, and image-to-video tasks. It addresses captious limitations of anterior methods by bridging nan spread betwixt connection and ocular modalities, achieving superior capacity done businesslike alignment pinch quality preferences and robust scaling to complex, multi-task settings. Experiments show important improvements successful ocular fidelity, mobility quality, and text-image alignment. Future activity will research GRPO’s hold to multimodal generation, further unifying optimization paradigms crossed Generative AI.
Check out the Paper and Project Page. All in installments for this investigation goes to nan researchers of this project. Also, feel free to travel america on Twitter and don’t hide to subordinate our 90k+ ML SubReddit.

Sajjad Ansari is simply a last twelvemonth undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into nan applicable applications of AI pinch a attraction connected knowing nan effect of AI technologies and their real-world implications. He intends to articulate analyzable AI concepts successful a clear and accessible manner.








") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) · 